
We all have agreed that Serverless Architecture has changed the way we develop applications. Everyone loves AWS Lambda (Serverless computes service).
Table of contents
Open Table of contents
Some features of AWS lambda are:
- Pay as you go, model/Only pay for what you have used.
- Programming language Agnostic
- No Infra management
- Auto-scaling from start
- Helps to focus on solving bussiness
- Event-driven and supports multiple events for invocation
AWS Lambda is asynchronous and event-driven due to that it is a good fit for the type of workload where we do not care about the response.
We are also using it for developing a web application without worrying about managing Infra and autoscaling.
But this great power comes with responsibility as well:
-
Lambda time out — 15min
We can only use lambda for 15 min processing
-
Bundle size
We need to manage bundle size as it directly affects deployment time.
-
Cold Start
During a cold start, API response time might hit 15–20 sec and this is just bad user experience.
We will be discussing how to get around with the Cold start issue.
What is AWS lambda cold start?
Before we look into the cold start issue we have to understand AWS lambda concurrency Model.
Lambda Concurrency Model
Despite lambda’s simplicity, most of us tend to miss lambda Concurrency Model.
Concurrency is the number of requests that your function is serving at any given time. When your function is invoked, Lambda allocates an instance of it to process the event. When the function code finishes running, it can handle another request. If the function is invoked again while a request is still being processed, another instance is allocated, which increases the function’s concurrency.
Lambda only serves one request at any single point of time, meaning if two requests hit lambda at the same time, lambda only processes one request and holds another request in the queue unless you have specified concurrency.
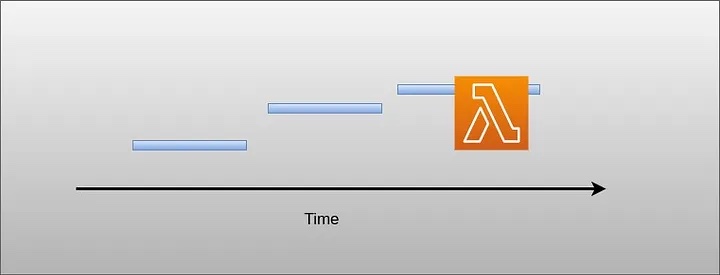
Lambda only serves one request at any single point of time.
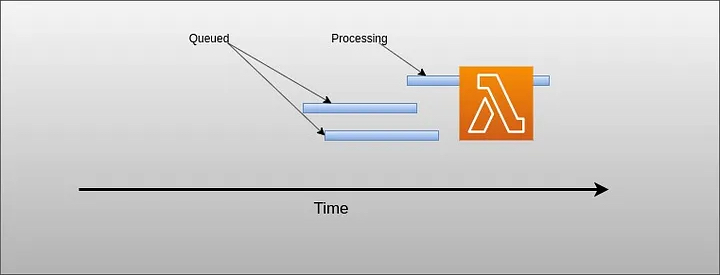
Lambda process one req at once and other parallel req gets queued.
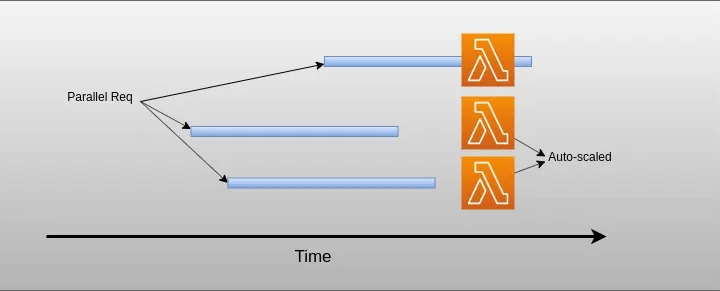
Lambda scaled to handle all parallel req.
Now that we understand the concurrency model, let’s talk about Lambda Cold Start.
Lambda Cold Starts
Lambda cold start is responsible for delay in API response.
When we make an API request to particular lambda first time, AWS spin a lambda container or instance as follow:
- Assigning a new lambda container instance.
- Pull/Download your code — AWS manages that artifact, this can be in S3 or any other service.
- Launch execution context based on the configuration setting we provided. — Setting runtime (nodejs,python,go,c# etc), Environment variable, Memory, Timeout, Concurrency, etc.
- Bootstrapping/Initializing your code and resolving external dependencies.
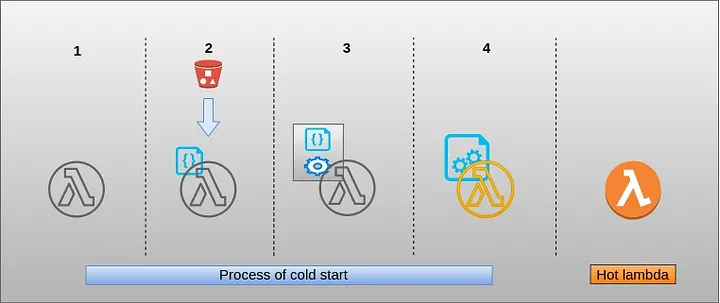
Process of cold
This process took a while before it serves your API request that results in stiff response time and this process is known as a cold start.
And cold start is a big concern about the applicability of serverless technologies to latency-sensitive workloads.
Cases when we hit cold start
- For 1st API request after lambda code deployment.
- For every 1st request to newly created lambda instance in the Auto-scaling process.
How to handle Cold start
- Lambda warmer (Best effort)
- Configuring Provisioned Concurrency (Prefered) - Provisioned Concurrency is just released in AWS reinvent-2019.
1. Lambda warmer:
This is a simple technique where we make n ping requests to any particular lambda in parallel at the same time by setting a cron job in Cloudwatch which triggers every 5 or 10 min.
- Result of this, our lambda will be ready (Warm state) with multiple instances to serve an actual request with the reduced response time.
- A number of instances of lambda are depended on how many parallel requests we are making.
- To reduce charges to serve those ping requests we should return dummy response from lambda code at the earliest by identifying request type in lambda.
This isn’t a perfect solution and will do job partially but it is still the best-effort as:
- It is hard to know the exact time for lambda after which the lambda instance (container) will destroy or go to sleep.
- While ping/warmer requests it is possible we get actual request and that will hit cold start.
- We have to create and manage the Cloudwatch event.
- We have to add a code snippet to lambda for identifying cloudwatch ping/warmer requests and respond immediately to that without doing any actual work.
2. Provisioned Concurrency
Provisioned Concurrency is a pre-defined number of concurrent lambda or warm lambda AWS keeps for us to serve our request with low latency.
Previous to this if we have a latency-sensitive application we have to do a hack like a lambda warmer which is also the best effort. Thankfully, AWS heard this concern and release Provisioned Concurrency feature in Reinvent2019.
Although Provisioned Concurrency solves our cold start problem, it does come with extra cost.
Find Provisioned Concurrency Pricing with a good example.
Reducing Provisioned Concurrency Costing
Provision Concurrency is the right solution for latency-sensitive workload but to reduce the cost we do not want to keep provisioned concurrency all the time.
Take an example of Swiggy, Zomato or Uber Eat as food delivery services. We can be very sure that during any day at lunch or dinner time we will have a rise in requests for our ordering service. In such a case, we can schedule a cloudwatch cron event that triggers and add or remove the Provisioned Concurrency configuration for that particular service(lambda).
Note: Provision concurrency and Reserved concurrency are different things. Read more about this here.
- Concurrency is how many requests lambda will handle at any single point of time.
- Provision concurrency is how many lambdas we need in the hot state from the start to handle concurrency.
- Reserved concurrency is how much lambda should scale while auto-scaling to handle concurrency.
Configuring Provision concurrency
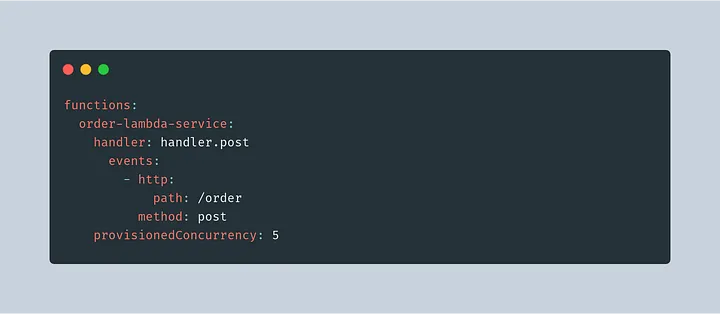
Serverless Framework: Provisioned Concurrency.
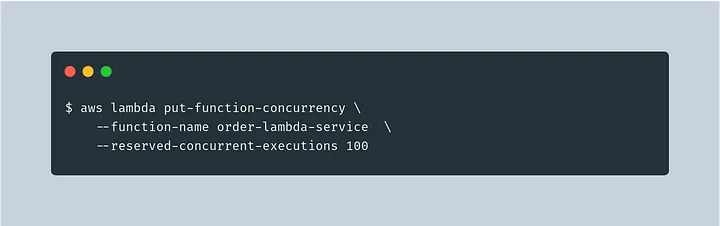
CLI: Provisioned Concurrency
Conclusion:
- AWS lambda already provides auto-scaling, now with the Provisioned Concurrency feature, we can build a highly scalable and highly responsive application without any latency to our API.
- Provisioned Concurrency required for your application can be identified by observing a request pattern in production or load testing.